[]
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
创建 Hive 数据连接前,需要手动下载驱动。
Hive 驱动下载地址:
Hive版本 | 驱动下载地址 |
|---|---|
2.0.0 | https://wyntools.blob.core.windows.net/dbdrivers/hive/2.0.0/hive.zip |
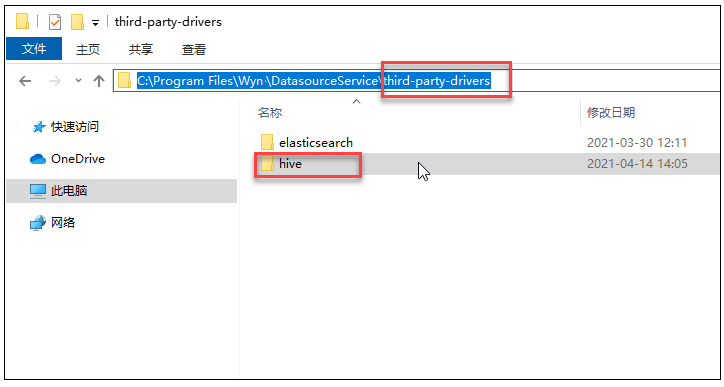
下载后,将压缩包解压。
在产品的安装目录 DatasourceService 下,创建目录 third-party-drivers/ (如此目录已经存在,则无需再创建一次),将解压的驱动文件放入即可。
type=info
提示
连接Hive数据源之前,还需由管理员在后台管理中将 Hive 数据源勾选,以使前台创建数据源时可以选择 Hive。详情请见数据源管理。
1. 在系统的门户网站中单击  ,选择数据源。
,选择数据源。
2. 在左侧数据源列表或者在右侧图标视图中选择 Hive。

3. 填写数据库配置信息。

参数 | 说明 |
|---|---|
名称 | 必填参数,自定义输入数据源的名称。 |
主机 | 主机名或主机IP。 |
端口 | 端口号,默认为10000。 |
用户名 | 连接数据库的用户名。 |
密码 | 连接数据库用户的密码。 |
使用配置连接字符串(高级) | 如果您勾选了此选项,则只需要填写此项与数据源的名称即可。填写此项的格式为: jdbc:hive2://myServerAddress:mySeverPort?User=myUser&Password=myPassword 比如:jdbc:hive2://10.32.5.243:10000?User=hive&Password=Aa123456 |
使用表/字段名称映射 | 修改数据源中的表名或列名,使其在数据集中显示为希望的名称。 |
4. (可选)可通过单击页面左下角的测试数据连接测试连接是否正常。

连接成功后,单击确定。

5. 单击创建,创建数据源。

6. 创建成功后,在文档类型分类下的数据源中可以看到刚刚创建的数据源。单击数据源的名称即可预览。

数据源创建成功后即可进行缓存/直连数据集,以供后续数据分析展示使用。
数据源创建成功后,可在门户网站中对其进行管理操作。
可以像其他文档一样进行编辑、设为主页、复制链接、管理分类、删除、下载、重命名等一系列管理操作,具体操作请详见第三章 门户网站介绍。

