[]
Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
本节为您介绍如何在系统中连接南大通用 ElasticSearch 数据库。
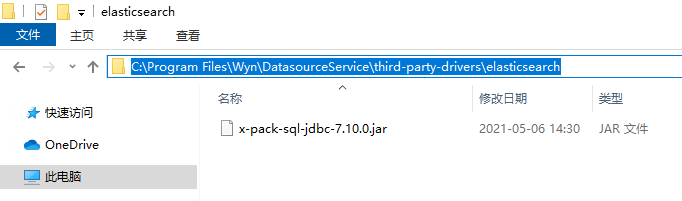
创建ElasticSearch 数据连接前,需要手动下载驱动。
Elasticsearch jdbc 驱动下载地址:https://www.elastic.co/cn/downloads/past-releases#jdbc-client
在系统的安装目录 Datasource service 下,手动创建目录 third-party-drivers/elasticsearch,将下载好的驱动放入即可
type=info
连接 ElasticSearch 数据源之前,还需由管理员在后台管理中将 ElasticSearch 数据源勾选并保存,以使前台创建数据源时可以选择 ElasticSearch。详情请见数据源管理。
1. 在系统的门户网站中单击  ,选择数据源。
,选择数据源。
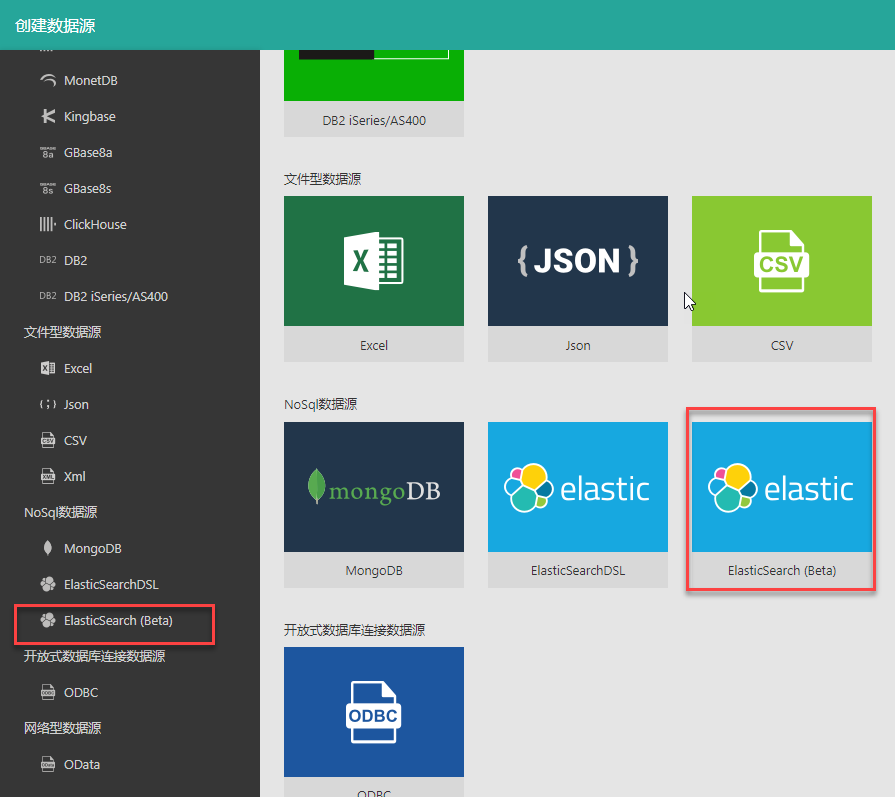
2. 在左侧数据源列表或者在右侧图标视图中选择 ElasticSearch(Beta)。
3. 填写数据库配置信息。
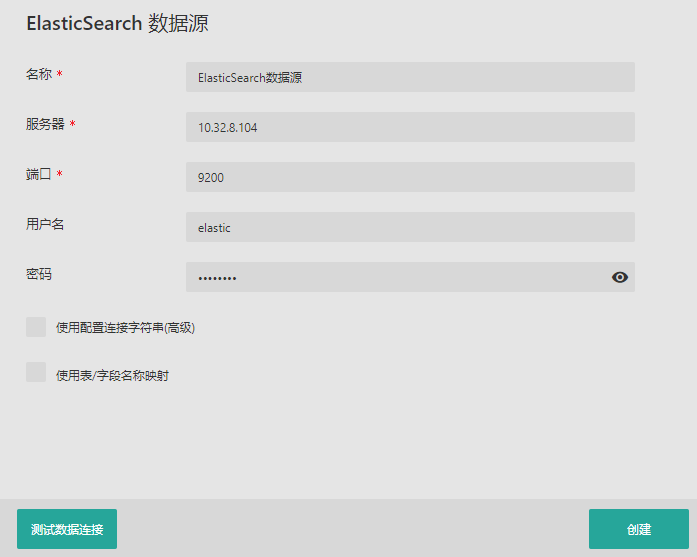
参数 | 说明 |
|---|---|
端口 | 端口号,默认为9200。 |
用户名 | 连接数据库的用户名。 |
服务器 | 服务器名或IP。 |
密码 | 连接数据库用户的密码。 |
名称 | 必填参数,自定义输入数据源的名称。 |
使用配置连接字符串(高级) | 如果您勾选了此选项,则只需要填写此项与数据源的名称即可。填写此项的格式为:
|
使用表/字段名称映射 | 修改数据源中的表名或列名,使其在数据集中显示为希望的名称。 详情请见使用表/字段名称映射(修改数据源表名或列名)。 |
4. (可选)可通过单击页面左下角的测试数据连接测试连接是否正常。
连接成功后,单击确定。

5. 单击创建,创建数据源。
6. 创建成功后,在门户站点中的未分类和数据源中均可以看到刚刚创建的数据源。单击数据源的名称即可预览。

数据源创建成功后即可进行缓存/直连数据集,以供后续数据分析展示使用。
数据源创建成功后,可在门户网站中对其进行管理操作。
可以像其他文档一样进行编辑、设为主页、复制链接、管理分类、删除、下载、重命名等一系列管理操作,具体操作请详见第三章 门户网站介绍。
我们系统当前支持的 SQL 标准是SQL92,但是 ElasticSearch 的原始 SQL 语法与 SQL92 有很大不同,因此我们选择 ElasticSearch 的 JDBC 驱动程序来支持标准 SQL,但是它有如下限制。
ElasticSearch 数据源不支持联合和连接操作,因此在数据集中,不支持将两个 ElasticSearch 表进行联合或连接操作。但是可以跨数据源与其他数据源中的表联合或连接。
在数据集中使用聚合函数时,不支持引用字段别名。
在数据集设计器中,不能使用“分组”模式,仅能使用“详情”模式。
当前版本中,不支持在 ElasticSearch 上使用任何参数。
在系统中无法使用不包含任何字段和内容,也即空的 Index。
仅支持 ElasticSearch SQL数据类型,不支持其他类型。也即只有以下 DataType 可以在数据集设计器中选择使用:NULL,BOOLEAN,TINYINT,SMALLINT,INTEGER,BIGINT,DOUBLE,REAL,FLOAT,VARCHAR,VARBINARY和TIMESTAMP
不支持使用函数 DISTINCT_COUNT。
ElasticSearch double 类型表示的范围比 javascript double 类型的范围更大,因此多余的数据将被自动拦截。
例如,如果为f或 double 类型,则数据库中显示的数字为-9223372036884775808,但是页面上的显示可能为-9223372036884776000。
某些双精度类型可能会降低精度。
例如,13533592802显示为13533592801.999998。
无法支持值为“ true”,“ false”或“”的布尔值字段。Elasticsearch JDBC 驱动程序仅查询值为true或false的布尔字段。
系统中不能显示 ElasticSearch 数据库中的 object 和 nested 数据类型,所以建议您尽量避免使用这两种数据类型。
